Fresh from the bench
Featured experiments
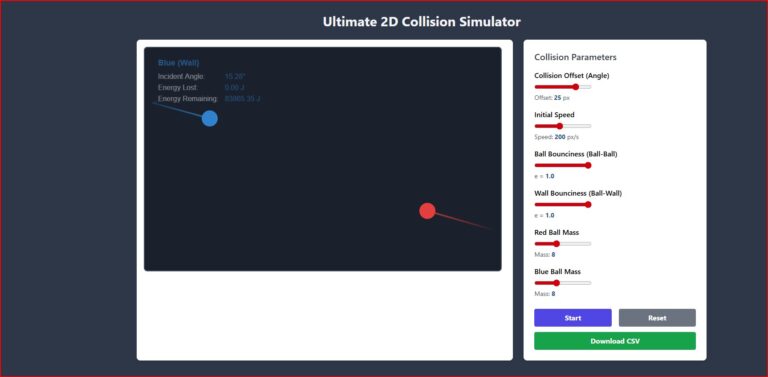
Mechanics
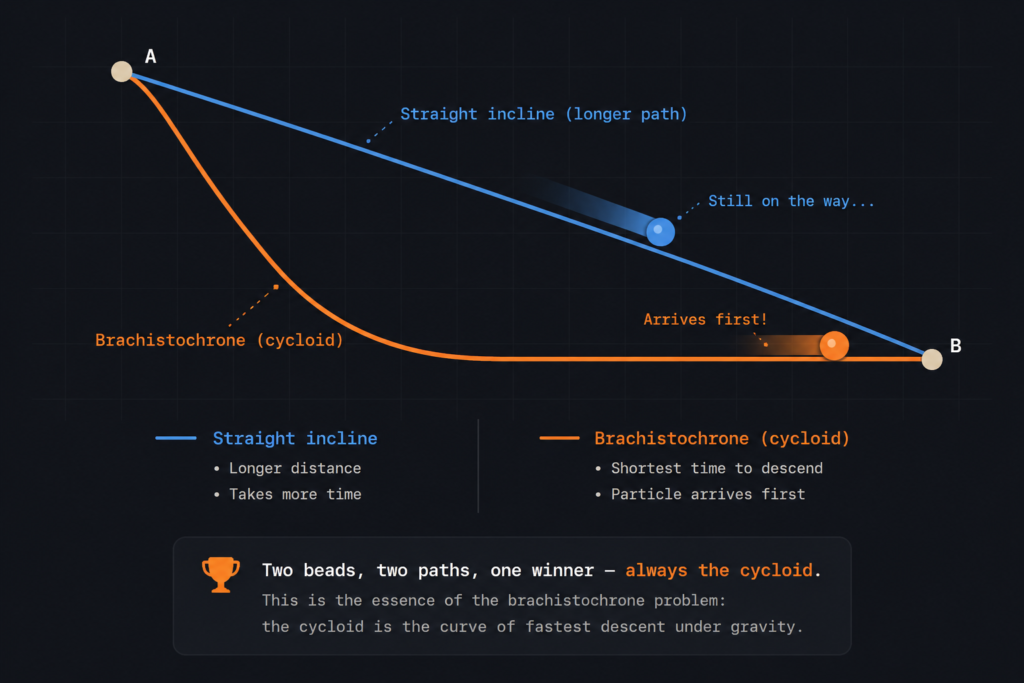
Brachistochrone
Which track is fastest — straight, circular or cycloid? Race them and find out why the answer shocked Newton's rivals.
Run simulation →
Mechanics
Ball Drop Experiment
Free fall with data collection — measure g like a real experimentalist, uncertainty analysis included.
Run simulation →
Thermal
Carnot Cycle Simulator
Watch the four strokes of the ideal engine unfold on a live p-V diagram — the simulation that finally makes Carnot click.
Run simulation →
Relativity
Minkowski Diagram Explorer
Spacetime diagrams you can drag — see time dilation and simultaneity break in real time.
Run simulation →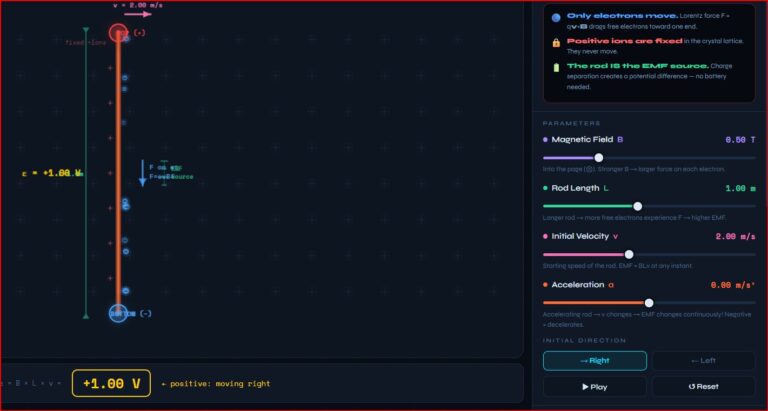
Electromagnetism
Motional EMF Lab
The physics hiding in plain sight — slide a rod through a field and watch the EMF appear.
Run simulation →
Solver Series
Mechanics Solver
One problem, multiple methods — forces, energy, momentum — solved side by side so you learn to choose the elegant path.
Open solver →